


In modern software development, teams often have to prioritize speed and less than ideal solutions to put out products quickly to keep up with fast-changing consumer demands.
Unfortunately, taking such shortcuts could have dire consequences in the form of heavy costs or technical debt that could take a toll on your code quality and your whole software development and delivery processes if left unattended.
In this article, we’ll explore what technical debt is, the causes and different types of technical debt as well as how to manage it, largely through the use of feature flags.
[toc heading_levels=”2, 3″]
What is technical debt?
The term “technical debt” was first coined by Ward Cunningham, one of the authors of the Agile Manifesto, in the early 1990s. Since then, the term has gained momentum and is a serious issue that many tech teams today still struggle to manage properly.
His reason for its name is that technical debt bears direct correlations with financial debt. Software development teams can take shortcuts to satisfy immediate business requirements, but the debt plus accrued interest will have to be paid at a later stage.
Technical debt is the consequence of action taken by software development teams to expedite the delivery of a software application or specific feature which later needs to be refactored or redeveloped.
Put simply, technical debt refers to the build up of technical issues during software development due to a number of causes which we’ll discuss in the next section.
If not attended to, technical debt can spiral out of control, resulting in the total breakdown of the software development and maintenance lifecycle.
Therefore, it is critical to ensure that DevOps and software development teams pay close attention to technical debt management and technical debt reduction methods.
Here are some warning signs to look out for:
- Buggy, difficult to maintain code
- Unstable production environments
- Bug fixes introduce more bugs
- Data inconsistency
- Decreased development pace and bottlenecks
What causes technical debt?
We can deduce that technical debt comes mainly as a result of delivering a release quickly at the expense of “perfect” code.
In other words, it often comes as a consequence of ineffective and inadequate practices to build software for a short-term benefit in the interest of saving time.
That is one major cause but it’s also more complex than that as technical debt can be due to a number of other reasons.
Some causes behind technical debt include:
- Time pressure: Teams today are under great pressure to deliver releases quicker than ever before to remain competitive and meet consumer demands fast.
- Poor code: This could be due to a number of reasons including use of tools without proper documentation or training.
- Insufficient software testing: Lack of QA support or automated testing means a lot of bugs could remain in the code undetected which gives rise to technical debt.
- Outdated technology: Over time, many technologies become obsolete and are no longer supported and could become a source of debt.
- Lack of skill: Teams can sometimes unknowingly incur debt because they lack the skills to write better code. For example, having junior developers working on building complex software beyond their skill and experience level is a sure way to accumulate debt fast.
Over time, all these factors could result in accumulation of debt that will need to be addressed. The real danger is not actually having the debt in the first place- as often that’s inevitable- but it’s allowing this debt to build up with no plan or strategy to pay it off in the future.
Types of technical debt
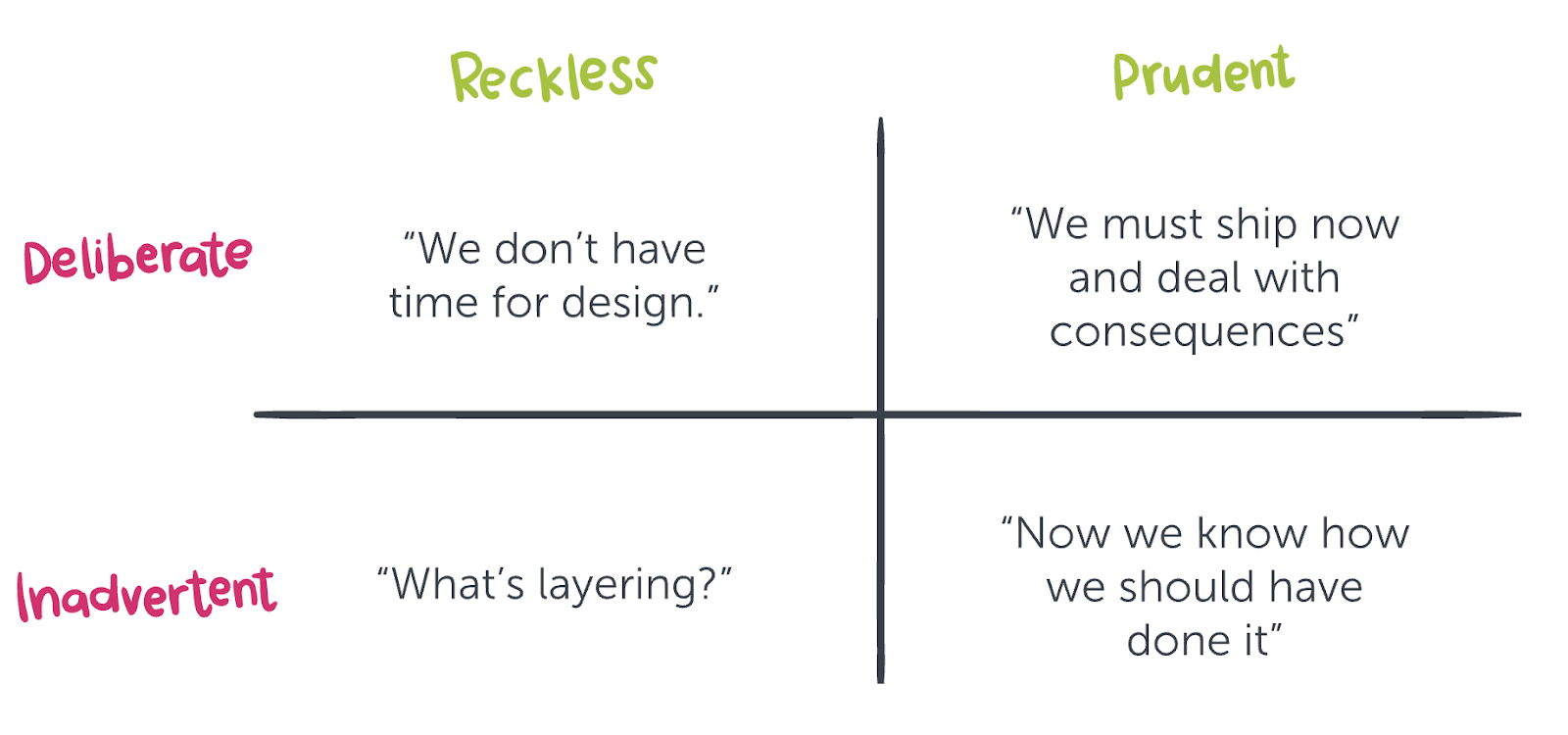
There are many ways to classify technical debt. One of the most popular ways comes from Martin Fowler’s technical debt quadrant.
The quadrant is based on the idea of not whether something should be considered debt per se but rather whether this debt can be considered prudent.
What does this mean exactly? Think of it as a way of answering the question of whether all technical debt is bad and the answer, according to the quadrant, would be “it depends.”
Martin Fowler’s technical debt quadrant seeks to categorize the types of technical debt according to intent and context.
Generally speaking, there are two overarching types of technical debt: intentional and unintentional (deliberate vs inadvertent).
Intentional technical debt occurs when software development teams choose to leave their code as it is, without refactoring or improving it, to reduce the time-to-market metrics. In other words, they choose to incur technical debt.
Unintentional technical debt, for its part, occurs when poor code is written and so the code quality will need to be improved over time.
Suffice to say, as soon as these technical debt-causing issues are highlighted, it is imperative to fix them as quickly as possible.
Let’s take a closer look at the 4 main types of technical debt, according to Martin Fowler:
- Reckless/deliberate: Teams possess the knowledge to carry out the task but decide to go for a “quick and poor quality” solution to save time and for quick implementation.
- Prudent/deliberate: Teams are aware of the debt they’re taking on but decide that the payoff for an earlier release exceeds the costs. However, in this scenario unlike the above, teams have a plan on how to deal with the repercussions of taking on this debt.
- Reckless/inadvertent: This is arguably the least desired form of debt where teams don’t have enough experience and blindly implement a solution without applying best practices. As a result, they’re unconscious of the fact that technical debt is being accumulated. Thus, no real plan to address this debt can be formulated.
- Prudent/inadvertent: This occurs when teams apply best practices during software development but still accumulate debt due to unexpected coding mistakes. Thus, this type of debt is unintentional. Teams have the necessary skill and knowledge to identify and pay off the debt but the experience serves as a learning opportunity for developers to optimize and improve the code for future projects.
When it comes down to it, deciding what to classify as technical debt is not always black or white. It requires putting things into context first. This is especially important when you think of the pressure on teams to put out products quickly to meet consumer and market demands.
This means that they will constantly have to deal with the dilemma between taking on technical debt or delaying a release. However, it’s more of a matter of how to deal with and manage this debt rather than avoiding it completely- which may not always be possible- to minimize negative impact as much as possible.
Types of technical debt to avoid
At this juncture, it is reasonable to conclude that teams should avoid technical debt. Additionally, it is imperative to minimize and eliminate tech debt, particularly reckless and deliberate code debt.
Over time, technical debt could become too expensive to fix the longer it remains unfixed as “interest” builds up the same way that financial debt accrues interest. Eventually, technical debt can lead to a code becoming harder to maintain as the foundation of the codebase deteriorates. This will ultimately result in lower-quality products with the company reputation taking a major hit.
Prudent tech debt is the partial exception to this rule. This form of code debt can benefit software development organizations as part of the reducing time-to-value methodology.
In other words, the advantages of delivering a product to market as soon as possible can outweigh the cost incurred by technical debt. However, it is critical to monitor the tech debt to ensure that its value does not spiral out of control, negating the benefits of the reduced time-to-value exercise.
How feature flags can help with technical debt
Feature flags can help reduce the technical debt accumulated during the development, testing, and deployment of a software application.
However, if feature flags are not monitored and maintained, they can increase the application’s technical debt.
Before we look at how feature flags reduce technical debt, let’s take a quick look at what a feature flag is:
“Feature toggles [feature flags] are among the most powerful methods to support continuous integration and continuous delivery (CI/CD)… [They] are a method for modifying features at runtime without modifying code.”
One of the most common sources of technical debt is the pressure to release a version of the software application.
The business demands that the software be deployed, and they don’t care how the developers make it happen. Feature flags are a valuable tool to help manage the “pressure-cooker” release environment.
There are several benefits to the use of feature flags as a software release and deployment aid, including:
- The risk of deploying a bug-ridden application is substantially reduced. Developers can simply switch off features that are not yet complete or thoroughly tested.
- By implementing a CI/CD methodology (continuous integration/continuous delivery), developers can often use feature flags to deploy new features without waiting for the next release to be deployed. In summary, this functionality reduces the time-to-value and increases customer satisfaction: A win-win for all.
- Implementing feature flags is also a means to negotiate with management about which functionality to complete before specified deadline dates, increasing the flexibility to develop and test features thoroughly before deploying them.
In summary, feature flags help manage and reduce technical debt by helping software development teams manage the development/testing/deployment lifecycle more effectively.
Feature flags are useful for dark launching, a practice of releasing specific features to a subset of your user base to determine what the response is to a new feature or set of new features. As an aside, this is also known as a canary deployment or canary testing.
Testing in production is another form of dark launching. By utilizing this option, you can assess the application’s health, collect real-world app usage metrics, and validate that the software application delivers what your customers want.
Feature flags can also create technical debt. While they play a significant role in mitigating technical debt in all other areas of the software development lifecycle, implementing them is usually via a set of complex if-else statements.
Therefore, in practice, a feature flag is an if statement defining the path between at least two different code paths depending on one or more conditions.
The following simple scenario describes how to implement feature flags.
Let’s assume that an e-commerce site offers free shipping for all customers that spend more than a specified minimum amount at one time.
This code sample is an example of a feature flag. If the total amount paid is more than $50, then the shipping is free. Otherwise, the shipping amount is the amount spent multiplied by the rate (a percentage of the total amount).
def ShippingYN(amt, rate) :
if amt > 50.0 :
shipping = 0.0
else :
shipping = amount * rate
return shipping
Best practices using feature flags to avoid technical debt
As with all aspects of software development and deployment, it is vital to observe the following feature flag best practices:
1. Feature flag management
As your organization matures in its use of feature flags as an integral part of the software development/testing/deployment lifecycle, it is vital to be mindful of the fact that some of the feature flags are short-term and should be removed; otherwise, they will add to the application’s complexity, resulting in more technical debt.
Consequently, it is imperative to have a plan in place to remove the flags before even setting them.
It is also possible, and a good idea, to track and measure different metrics for each feature flag, such as how long it has been active, its states (on/off), different configurations, and how many code iterations it has been through.
Once your feature flag has been through the required number of iterations to code and test a feature, this flag must be removed and the code merged into your code repository.
Note: Before removing a feature flag, it is a good idea to evaluate its function and purpose; otherwise, there is a risk, albeit slight, that the flag might still be needed and is erroneously removed.
A vital part of the feature flag management process is to define and implement temporary and permanent flags.
1.1 Temporary feature flags
As highlighted above, if a feature is designed to be rolled out to every application user or you are using the feature as a short-term experiment, it is critical to attach a monitoring ticket to this flag to make sure it is removed once the feature has been deployed or the experiment is concluded.
Examples of these temporary flags which can last weeks, months, or even quarters, include:
- Performance experiments: A performance experiment is similar to A/B testing, where two versions of the feature are deployed with the idea of determining which one performs better. A/B testing employs the same construct in that it deploys two versions of an element to the application’s user base to select which one users prefer.
- Painted-door experiments: These experiments are only used in the early phases of the software development lifecycle and are User-Interface mock-ups to determine any customer interest. Once the consumer interest has been determined, these flags can be removed.
- Large-scale code refactoring: It is a good idea to deploy code refactoring changes behind a feature flag until you are positive that the functionality has not been changed or broken. Once the refactoring exercise is complete, you can remove these feature flags.
1.2 Permanent feature flags
Permanent feature flags are used to implement different features or functionality for different groups of users.
As a result, it is reasonable to assume that these flags will remain in the software application indefinitely or at least for a very long time.
Therefore, it is vital to ensure that they are monitored, documented, and reviewed regularly. As with the temporary flags, there are several different types, including:
- Permission flags: These feature flags are helpful when your product has different permission levels, such as the ability to create journal entries in an online financial general ledger or whether users can view a list of these entries. A second use case for these flags is your SaaS application has different subscription models like Basic, Professional, and Enterprise.
- Promotional flags: These flags help implement regular promotions. For instance, let’s assume your e-commerce store offers a Mother’s Day promotion every year where specific products bought include the shipping costs.
- Configuration-based software flags: Any software driven by config files will benefit from using feature flags to implement the different possible configurations. A typical use case for config flags is the layout of the User Interface.
- Operational flags: These feature flags help manage a distributed cloud-based application. For example, additional compute engines can be spun up when the workload reaches a specific level.
2. Use a central code repository
Feature flags or toggles are most commonly stored in config files.
Another option is to keep them in a database table. However, let’s look at how to manage these config files. Large systems can have many if not hundreds of feature flag settings. Apart from using a database table, the only way to manage these settings is to store them in config files.
The best way to maintain the config files is to upload these files to a feature flag library in a central code repository like Git.
Not only is Git good for keeping control of these files, but it is also a valuable version control system. Developers can use it to create feature branches of config files used during the software development process without negatively affecting the production version of these files.
Once the config files have been updated and tested, they can be merged back into the Git master branch using a merge request.
3. Adhere to naming conventions
It is absolutely critical to give your flags intuitive, easy-to-understand names, especially for long-term flags, although it is a good idea to include short-term flags in this best practice.
Naming the feature flags, flag 1, flag 2… flag 100 will not help people who have to work with these flags in the future.
A good example of wisely named feature flags can be found in the scenario highlighted above.
It is reasonable to assume that the flag, AdvancedSearchYN, is one of hundreds of flags used in our eCommerce application. Even if they are the only two flags used, it is still advisable to give them intuitive, related names.
For more details on the best way to manage feature flags to keep technical debt at bay, download our feature flag best practices e-book.
4. Use a feature management system
Using a dedicated feature flagging system is a great way to manage flags in your code so you don’t find yourself with piles of technical debt from unused or stale flags.
AB Tasty’s server-side feature enables you to remotely manage feature flags and take control over how, when and to who features are deployed to mitigate risk while optimizing user experience.
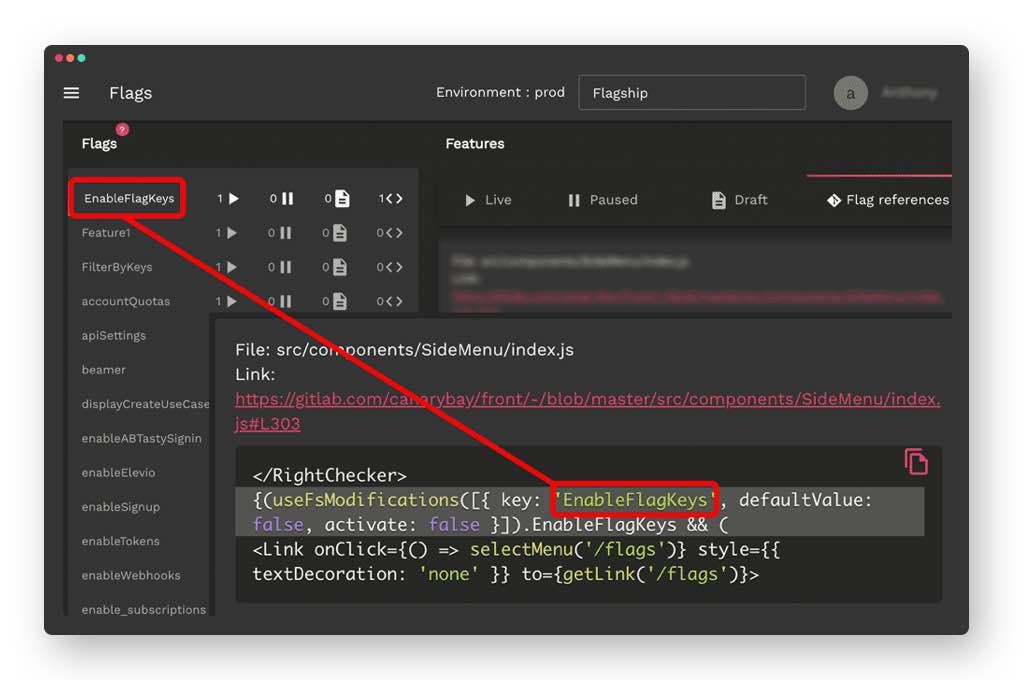
To help with technical debt management, AB Tasty provides dedicated features to keep control over your feature flags. Two of them are especially useful in this regard:
- The Flag Tracking dashboard lists all flags setup in the platform, with their current values (ex: on/off) and campaigns that reference them. This way, you can easily keep track of every single flag purpose (ex: flag 1 is used in progressive rollout campaign X, while flag 2 is used in feature experiment Y). When you manage hundreds of flags, it turns out to be a real time saver.
- The Code Analyzer is an advanced Git integration to see where your flags are used in your repository. In conjunction with the flag tracking dashboard, you can quickly find flags in your code that are not referenced in any campaigns. It also deeply integrates with your current CI/CD pipeline. As a CLI and a Docker image, it analyzes your codebase and detects the usage of flags everytime code is pushed to a specific branch or tag. This way, your flag dashboard is always in sync with your codebase. On one hand, you can safely remove flags if they are not referenced in campaigns, and on the other hand you make sure that flags your campaign is relying on are indeed available in your code. View code on Github.
Final thoughts
As described throughout this article, feature flags in DevOps and software development play a fundamental role in managing and reducing technical debt.
Consequently, it is vital to implement a feature flags framework as a foundational part of the software development lifecycle.
Cobbling it on afterward can increase the risk of incurring more technical debt, especially once the system grows in scale. Thus, these feature flags must be carefully maintained and monitored to ensure that they don’t amass additional technical debt.
Finally, it is essential to be mindful that, while technical debt is primarily seen as a negative, there are instances, as described by Martin Fowler’s technical debt quadrant, where incurring prudent and deliberate tech debt can be beneficial.
It is also worth noting that both Agile and Scrum use the concept of technical debt in a positive way to reduce the time-to-value of a new application or feature release, driving sustainable growth through customer satisfaction.
